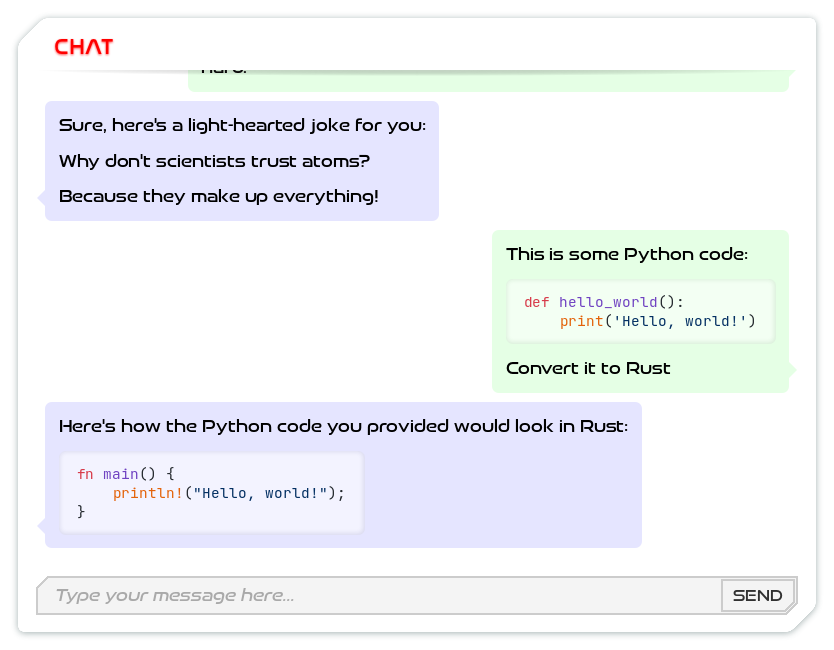
ZAMM now formats code snippets included in conversation.
There’s also small fixes, like getting chat bubbles to resize properly when the window resizes. A new feature that likely isn’t very noticeable is automatic updating for future releases of the app. Behind the scenes, I did a number of code cleanup tasks and fixed all issues with development on Windows. Outside of the app itself, I made a number of small changes to this website, researched and wrote this blog post, and made a contribution to an upstream dependency. (Other projects that your project depends on are known as “dependencies.” They are “upstream” because changes to them ripple “downstream” to affect your project. If the upstream project isn’t doing quite what you want it to do, you can often make contributions to it to make life easier for yourself.)
Outside of software altogether, I’ve successfully wrapped up all my remaining business in Australia and made the move back to Cambodia, where I have been busy setting up my new life. I say all this to help myself see that I have actually done a decent number of things over the past month, because it is otherwise a bit disappointing when it feels as if I’ve barely made any progress at all on where I’d like this app to be.
Perhaps one of the biggest improvements is how I’ve increased the comprehensiveness of my backend testing setup with configurations such as this:
request:
- chat
- >
{
"provider": "OpenAI",
"llm": "gpt-4",
"temperature": null,
"prompt": [
{
"role": "System",
"text": "You are ZAMM, a chat program. Respond in first person."
},
{
"role": "Human",
"text": "Hello, does this work?"
}
]
}
response:
message: >
{
"id": "d5ad1e49-f57f-4481-84fb-4d70ba8a7a74",
"timestamp": "2024-01-16T08:50:19.738093890",
"llm": {
"name": "gpt-4-0613",
"requested": "gpt-4",
"provider": "OpenAI"
},
"request": {
...
},
"response": {
"completion": {
"role": "AI",
"text": "Yes, it works. How can I assist you today?"
}
},
"tokens": {
"prompt": 32,
"response": 12,
"total": 44
}
}
sideEffects:
database:
endStateDump: conversation-started
network:
recordingFile: start-conversation.json
I quite like this setup. Not only does it explicitly state the exact request-response pair that is expected of the Tauri API, but it also states the exact interactions that are expected with the database and the network. The backend tests use this to check that all expected duties are performed during request handling. The frontend tests use this to check that the correct request is being sent, and gets in return the exact response it needs to handle.
Here is an example of an API call that affects both the disk and database:
request:
- set_api_key
- >
{
"filename": ".bashrc",
"service": "OpenAI",
"api_key": "0p3n41-4p1-k3y"
}
response:
message: "null"
sideEffects:
disk:
startStateDirectory: shell-init/with-newline/start
endStateDirectory: shell-init/with-newline/end
database:
endStateDump: openai-api-key
The optional disk write updates your shell init file to export your OpenAI API key. This is only useful on the Mac and Linux, because I haven’t yet figured out how to programmatically edit environment variables on Windows. The database write allows the app to read your API key without requiring you to restart the terminal session or re-login. Since I’m using a local SQLite database, the database write is actually also a local disk write, but they’re conceptually different enough that I think it makes sense to separate them this way.
I think this is pretty neat. I haven’t seen this sort of test setup before, so perhaps there’s value in me eventually making this a proper package for others to use. But adapting bespoke code tailored for specific contexts into generic code usable in unpredictable ones typically requires non-trivial time and effort, and that is not how I currently wish to spend my limited resources.
In retrospect, it would have been better to specify the request-response pair as an external file, just like I do with the side effects. After all, the backend may need to perform different disk or database writes depending on the current state of the disk/database, whereas the frontend doesn’t care so long as the request and response stays exactly the same. But cleaning up and reorganizing code also requires non-trivial time and effort. After having already spent much of this release cycle doing just that, it is no longer how I wish to spend my limited resources.
In the previous post, I qualified my test ethos as being “near total discipline” with regards to the bits being written to disk or sent over the network. The main reason I had in mind for this qualifier was that I was testing my database writes by querying afterwards for successful insertion of a new row into the database. While this works, it doesn’t provide the same amount of reassurance as checking against a dump of the database. For example, if I change the way that data is serialized/deserialized to and from a JSON blob, the check for a valid database write will still pass, but the dump will alert me that I am making a potentially backwards-incompatible change.
For those not familiar with the terminology, serialization refers to the way that meaningfully structured data is rendered into a meaningless one-dimensional string of 1’s and 0’s, which is ultimately how data must be persisted on disk. It is like storing your thoughts in a paper essay. The ink on a page may not be as directly meaningful as thoughts already in your head, but it does survive a lot longer and is much easier to share than thoughts in your head. Moreover, just as a computer must decide what linear order to produce its 1’s and 0’s in, you must also decide for your essay what linear order you want to present your ideas in, and ultimately the exact order of the words you want to use.
Meanwhile, deserialization refers to the way that this meaningless string of 1’s and 0’s is then parsed back into a meaningful representation that the program can actually use when it’s running. It’s like having thoughts in our head after we read an essay. Our mind doesn’t act on the words, it acts on the thoughts in our head. As such, we must first read the words, make connections between the different concepts presented, and make connections between those new concepts and what we already understand about our world. Only once the ideas are in our heads can we start thinking about them. Similarly, computer programs must generally first create a meaningful structure out of 1’s and 0’s before they can start to have interactions with the information contained within. The main exception would be software such as Cap’n Proto that make the in-memory and on-disk representations of data exactly the same, or software that only needs to engage with their data at a superficial level — for example, programs that just copies data without caring about what that data contains.
Backwards compatibility refers to the need to make new things work with existing things. For example, notice how 35mm film rolls come in a protective cartridge:

whereas medium format film is only held together by a single sticker, which makes it feel precarious to store after shooting:

This may have possibly been because there were historically two decades of camera technology development between when medium format was first introduced to consumers, and when 35mm came on the scene. If someone today were to add casing around medium format film rolls, that extra casing likely wouldn’t fit into any existing medium format cameras. This film roll would be backwards incompatible with existing cameras, so you’d need to manufacture a new medium format camera just for this roll. This new camera would most likely also be backwards incompatible with all existing medium format rolls. Chicken, meet egg. This problem is not insurmountable if enough people are interested in the solution, but as it is, the analog camera market is rather small.
Of course, the best possibility would be to create an improved film roll that works with all existing cameras. Innovation is most accessible when it is able to pay homage to prior art. Yet sometimes a break from tradition is needed, and forcibly tying ourselves to old ways of being can prevent us from making full use of new possibilities. My main goal with the aforementioned testing is not to stop myself from making backwards-incompatible changes, but to make myself aware when I do so.
This constant churn of innovative but backwards incompatible software produces a phenomenon called bit rot. Here, I’m referring to the software phenomenon, rather than the hardware phenomenon that concerns the physical decay of information. You see, even though our digital items don’t decay like our physical items do, the digital environment in which these items exist slowly changes over time. Eventually, the original environment becomes lost or inaccessible altogether, rendering old digital artifacts useless unless efforts are made to reconcile them with a more modern reality.
Take for example English, which has existed as a language for over a millenium at this point. Back in the 1100’s, the phrase “a gay man” would originally be taken to mean “a joyful male.” By the 1600’s, the meaning of “gay” was extended to take on general connotations of licentiousness, such that “a gay man” might refer to “a womanizer.” And of course, these days that phrase primarily refers to a homosexual male. The words may have remained the same (insofar as a word remains the same word when its spelling or pronunciation changes), but shifting cultural attitudes and linguistic usage causes the default interpretation of this phrase to radically differ over the centuries. Unless efforts are made to reconcile Old English texts with contemporary usage, even native English speakers will struggle with their interpretation. (“Blood is thicker than water” would be an even better example, except that it appears to be a misconception that the phrase actually meant the opposite of what it does now.)
Repeat this again and again for millenia, mixed in with some political discontinuities, and you end up with extreme scenarios where you are unable to read well-preserved pieces of ancient text at all:

We are unable to read these ancient symbols, not because we are illiterate or because the symbols have physically degraded too much, but simply because the world has long moved on from the cultural and linguistic context in which those symbols were etched.
A similar situation can occur in the digital realm, wherein your computer still clearly works and you still have code that is clearly intact, and yet the code no longer runs properly the way it used to. Immortality cannot be achieved by simply avoiding physical decay; code starts dying the moment it is written because the rest of the software world is continuously moving on with daily contributions from millions of developers. Each little change has the potential to invalidate prior assumptions made about the context in which your code runs. If you’re lucky, your code won’t even run in a new context, making it completely obvious that changes are needed. If you’re unlucky, the code runs but does something different from what it did before, making the new error insidiously subtle. (Think about talking to an English speaker from an older time about gay men, without either of you realizing you’re referring to completely different things.)
Even wealthy megacorps are not immune to bit rot from their own software. Why did Microsoft’s Snipping Tool stop recording videos after a recent Windows update? Because the rest of Windows has moved on, invalidating whichever crucial assumptions Snipping Tool may have made about how Windows works, and Microsoft does not care enough as an organization to expend resources on making sure that every feature of Snipping Tool still works. Apple too has new problems pop up around syncing music albums between the Mac and the iPhone. After all, Mac OS, iOS, and iTunes are all actively developed software that sometimes grow apart in subtly backwards incompatible ways. Who is there to notice that music no longer syncs fully, except for hapless customers that can only complain into the void?
But if there is such a thing as bit rot, then there must surely be an analogous bit life, wherein actively developed software are organisms growing as part of a living digital ecosystem. I am of course anthropomorphizing code here, but I think the framing holds up for personal purposes, if not scientific ones. If I am to think of ZAMM as something to be gradually grown and then maintained over time, rather than a one-and-done deal that I just need to cross the finish line for, it personally becomes much easier to deal with instances of bit rot during development.
For example, on separate occasions, prettier and Tauri driver stopped working for me all of a sudden. Instead of seeing these as unfortunate mishaps that get in the way of the finish line, I now see them instead as an integral and expected part of what it means to keep a software organism alive. You wouldn’t begrudge a plant for needing help with water every now and then; you shouldn’t begrudge a software organism for needing help reconnecting with their dependencies either. (Yes, I did start version pinning everything I can think of. I do disagree with the decisions of Yarn and Cargo to not make use of their .lock files by default. I don’t know why I’ve been repeatedly exposed to prettier updates despite pre-commit using a specific Git version tag in its config.)
As minimal as ZAMM is right now, the credits page already lists around 20 other projects that it depends directly on:
Those projects depend on a number of yet other projects, and many of those projects also recursively depend on yet other ones. All in all, that adds up to 1,346 total dependencies for the frontend and 535 total dependencies for the backend. The user-visible features of ZAMM may just be the tip of the iceberg when you take into account all of ZAMM’s supporting development and test infrastructure. But all of that is itself just the tip of the iceberg when you consider the nearly 2,000 other projects ZAMM depends on. ZAMM rests on top of an enormous iceberg that is also simultaneously continually growing and shifting underneath ZAMM. It really is just a tiny organism inside of a thriving software ecosystem.
I dream of a day when LLMs liberate us from having to manually toil to keep our software organisms alive in a world that is slowly burying them into irrelevance. After all, if an AI could understand the original context within which some code was written, and it understands how the world has changed since then, perhaps the AI could automatically adapt the code to its new environment while preserving its original intent. Perhaps I don’t need to spend such a considerable amount of time testing every last detail of this app. But if/when that day comes, my tests will be ready to serve as exhaustive documentation for what exactly my intent with ZAMM was.
Discuss on HN or below: