v0.1.5: Odds and ends
| Published |
Discuss on HN
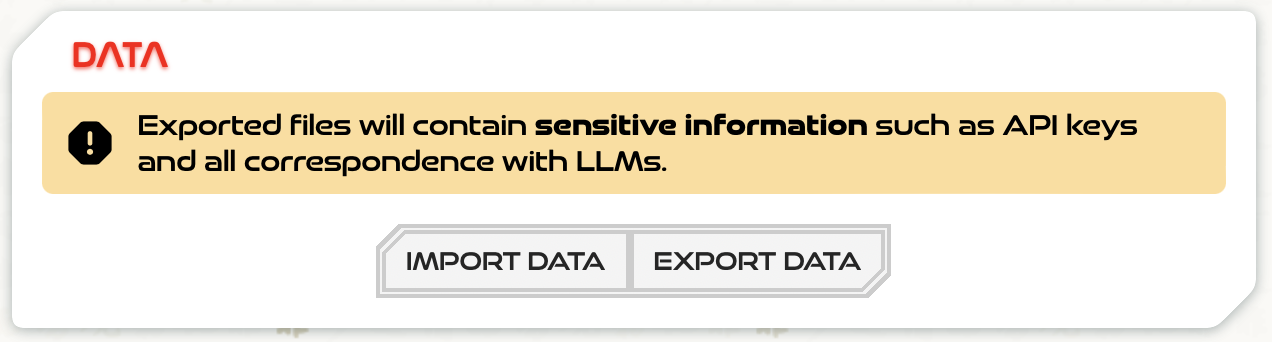
ZAMM now supports data import and export!
Each sidebar tab also now remembers the last page you were on when you navigated away from it. Form buttons show up as disabled during form processing. Font and window sizes are shrunken down by default on the Mac, because I finally got a new Mac to run things on, and boy did I find the ZAMM UI to look garishly large on Retina screens!
Conversations from Ollama and LM Studio can now be imported, although the steps to do so are a bit clunky. You need to go to the database page on the sidebar, then click on the ”+” icon on the top right to start a new LLM API call, then click on the import link, and finally paste in either the commandline output of Ollama, or the export from LM Studio. I mainly just wanted to make sure this import was even possible at all, and didn’t spend any time on getting the UI to make more sense.
The lines of the Dao De Jing text have already been displayed in columns on the background, but now these columns also run from right to left, as Chinese text is traditionally supposed to. The rightmost fully visible column on the screen is now always going to be the first line of the DDJ:

Furthermore, the background animation no longer glitches out at infinite speed when the general animation setting is turned off but background animation is still kept on.
The default window size on app startup has been made larger to allow for a two-column layout on the settings screen:

The database page can now also handle showing API calls from future versions of ZAMM that involve as-of-yet unknown LLM “providers” (i.e. how I’m lumping OpenAI and Ollama together as different ways you can access LLMs) and prompt types. I’ve been working on Ollama integration, and was annoyed to see that v0.1.4 of ZAMM can’t render the main database screen at all once a single unrecognized API call from a future version of ZAMM is introduced.
Behind the scenes, I got tests to pass on the Mac, and also wrote some simple Rust macros to reduce much of the boilerplate involved in running backend tests.
In other news, I celebrated my 29th birthday a few weeks ago! I was also able to bring to a head the mental conflict I talked about in the previous release, and it had a big enough impact on productivity that I wasn’t able to make a release in July. However, I feel like that experience deserves a proper write-up, and in the meantime I want to get a release out as soon as possible so that I can start using all the tweaks mentioned above. As such, I’ll confine this blog post to random topics, much like the changes to ZAMM itself for this period.
Carelessness with saving Ollama conversations
Last month, I got myself a MacBook Air with the new M3 chip. One of the first things I tried was conversing with Llama 3 via Ollama. The LLM token generation is many times faster than on my Windows laptop, which has an RTX 3080 laptop GPU. I showed Liza, who then wanted to try Ollama out on her own laptop. She proceeded to have quite an intimate chat with Llama 3, wherein they collaboratively crafted a fantasy world together.
I hadn’t foreseen Liza getting emotionally attached to a conversation with Llama 3, so I now scrambled to find out how that conversation might be salvaged before the Terminal window was closed or the computer rebooted for whatever reason. We first copied all the terminal output out to the Notes app as a backup. Then, my initial Google searches brought me to this and that, making it clear session persistence was not possible with the Ollama CLI.
I installed LM Studio instead and showed Liza how to manually edit a conversation there in order to restore the entire conversation history she had with Ollama. Unfortunately, Llama 3 somehow ran a lot slower on LM Studio than on Ollama. We tried killing the Ollama process and even restarting her computer, to no avail. Even on a fresh reboot, simply loading Llama 3 through LM Studio would crash her Mac. It seemed clear that we would have to keep using Ollama on her machine after all — and if Ollama itself doesn’t support session persistence, then ZAMM can take on that role by relegating Ollama to a purely behind-the-scenes LLM server. If there’s such a thing as “go fever”, perhaps I succumbed to “build fever.”
Somehow, it was at this point that I finally decided to do another Google search, and stumbled on this issue. At the time of the issue, Ollama still did not support saving or loading conversations, but the comment mentioned a future update for version 0.1.21 that would. Our Ollama version was already at 0.3.3, so I tried out the /save and /load commands as mentioned. While I didn’t save my own conversation at the time, the following is the closest reproduction I can find. It’s based on the exact same inputs that’s saved in my ~/.ollama/history, but has slightly different outputs:
>>> hi, i'm going to try to test the save feature here
Hi! Go ahead and test the save feature. I'll be here waiting for your
results.
>>> /save asdf
Created new model 'asdf'
And then in a new Terminal window:
>>> /load asdf
Loading model 'asdf'
>>> hey did it succeed?
Since we just started our conversation, there's nothing to save yet.
You're free to enter some text or make a request, and if you want to save
our conversation, just let me know when you're ready!
Aha! You think the conversation has just started? Clearly the load feature doesn’t work at all! Phew, I had not in fact been negligently careless after all in restarting the computer without first figuring out how to save the session on a live Ollama process.
I then went on to start coding support for Ollama in ZAMM, since it was a chore that I was theoretically going to do sooner or later anyways. I quickly added the conversation import feature, and then noticed and addressed the problems with ZAMM v0.1.4’s handling of unknown future data. I was two days in when I somehow decided to give the Ollama session restore capabilities a second try — no way they have such a major feature that’s completely broken. Lo and behold, this time it worked unambiguously. I ended up writing a script to restore the conversation using information from this blog post, so all was well in the end.
In retrospect, if I had cared to look closer at Ollama’s response instead of being quick to confirm my own biases about not having been negligent, I would’ve probably noticed that it contained traces of the previous context in there after all. And if I had only gone on to ask it one more question to make sure:
>>> What was the first message I sent you?
Your first message was "hi, i'm going to try to test the save feature here"
I would’ve realized that the save feature worked after all.
In fact, Google serving up outdated search results on Ollama capabilities wouldn’t have even mattered if I had simply paid closer attention to the help menu and seen that the feature already exists:
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.
I am reminded of my roommate. I have a wonderful roommate who is unfortunately also a careless person, in every sense of the word that I can think of. Contributing to the carelessness is the fact that he won’t notice things, and he will forget things. The very first time I started to realize this about him was when he used his own hand as a cutting board. Knife in right hand, chicken in left hand. He gave himself a cut, so I gave him a band-aid and asked why he wasn’t using the cutting board. Turns out he hadn’t noticed its presence in the kitchen. I suppose he thought it was too late to stop, because he went on to give himself another cut, and I went on to give him another band-aid. “Dude, you gotta be more careful, man!” I exhorted (“by using the cutting board!” I wanted to add, but didn’t), and he agreed. Then came a third cut, with an accompanying third band-aid. My roommate prided himself on having learned cooking merely through observing his mom, without any formal guidance. I suppose he must have observed imperfectly.
I remember when my dad taught me about cutting and using knives in general. You have to be careful around knives, of course, but you also can’t just be careful. Accidents can and will happen, and when they do, where will the knife go? You have to think about that situation in advance. Always make sure that if the knife slips or cuts the wrong way, no fingers will be in its potential path. Always apply force with the knife in a direction away from your body: if you’re opening a box with a box cutter, make sure you’re cutting outwards, so that if the cutter hits a snag, you don’t end up impaling yourself when you cut through the snag. He had a similar philosophy towards fire: if you have a habit of walking away while food is cooking, sooner or later you will forget that you left the stove on. Better to simply stay put in the kitchen for so long as there are open flames.
I am reminded also of tech outages. In the physical world, post-mortems are another word for autopsies, which try to figure out the cause of someone’s death. In tech, post-mortems are reports written after a major catastrophic failure (for example, all of Facebook going down) to try to understand just what the hell happened, why this catastrophe wasn’t prevented by existing processes, and how the organization could protect itself from this in the future. A typical report will have a timeline of what happened at what time, including details on:
- The technical causes of the failure: e.g. at 7:02 PM EST, this code change was pushed; at 7:03 PM, servers started crashing
- The flow of information between humans: Who first noticed it, how they noticed it, how that information was communicated to whom, etc.
- Theories that were formed and solutions that were tried
Having established the facts, a report would then try to identify areas for improvement. For example:
- If there’s a bug in existing code that causes the system to crash, that obviously needs to be fixed
- If the problem took a long time to be noticed, then perhaps automated monitoring needs to be put in place to immediately catch such problems the next time they happen
- If the problem was quickly noticed by different people on different teams, but they took a long time to haphazardly piece together different pieces of the puzzle, then perhaps there should be more clearly defined roles and better information flow for the next time a problem occurs. Perhaps have one person temporarily assume leadership command over everyone else in this situation, so that at least someone somewhere has a bird’s eye view of everything that is going on
- If the problem was quickly noticed and an obvious solution quickly found, but it took a long time to get in touch with the guy who has permission to update the databases, then perhaps this organizational failure should be amended by giving more people emergency access to the database, or perhaps by making it clear who the emergency contact for the database is at any given time, and how they should be contacted
- If the problem was noticed but the symptoms were confusing and the decision makers involved had incorrect theories as to the cause, resulting in them applying incorrect fixes that worsened the problem (as was the case for the Three Mile Island incident), then perhaps the control system dashboards should be redesigned to give less misleading output, or perhaps there should be better training on how to correctly interpret the output.
Generally speaking, there’s a culture of “blameless post-mortems” in the software industry that focuses on blaming processes rather than individuals. From the organization’s perspective, if you genuinely want to get to the bottom of how a failure happened, you would obviously want everyone involved to be honest, vulnerable, and cooperative with your investigation, rather than trying to cover up, mislead, and misdirect by pointing fingers at each other. Moreover, humans are fallible. If it’s an easy mistake to make, then simply firing the person who fucked up doesn’t exactly prevent the next person in their position from eventually making that same mistake. Think Chernobyl (I highly recommend the miniseries): yes, Dyatlov did a very bad thing, but it was the entire apparatus of Soviet mismanagement that allowed one man’s overconfidence to blow up to the extent that it did. (Of course, if you’re like the Soviets and are more interested in looking good than in actually fixing the problem, then putting all the blame on human operator error is a sensible way to go.)
And so, I wonder for myself: how could I avoid making the same mistakes I made with Ollama in the future? My roommate may be careless in ways that even I find extreme, but I have also been known to be careless to people around me. If there’s one piece of feedback that I have gotten consistently throughout my career, it’s that I program fast enough, but not carefully enough. How can I be more careful, in a way that isn’t as futile as saying “Dude, you gotta be more careful, man!” to my roommate?
I have to admit that I didn’t really care about my career in my early 20’s, so all advice from my managers fell on deaf ears. I was already getting paid more money than I knew what to do with, so what was the point in climbing the corporate ladder? Doing well in corporate still doesn’t feel like an inherently meaningful objective to me, but I am now finally starting to see the value in avoiding unforced errors of negligence, and so I must finally start asking myself what I never asked my managers: How do I actually become more careful, without simply telling myself “Be more careful” and then going on to make more careless mistakes?
Being careful still doesn’t usually appeal to me, and doesn’t come naturally either. It’s not that I consciously decide, “Okay I’m just going to be careless with this one because it doesn’t matter.” It’s that I don’t even think to be careful about something, and I go ahead and just do it, before realizing after the fact that I should’ve perhaps first given it a second thought (no pun intended). The urge to be careful only comes on naturally when I encounter a situation in which I’ve been bitten by my own carelessness before. In particular, I have learned to be careful about writing tests for my code, which is helped by the fact that tests are something extra I can do, and I love doing things. Like how buying bullion seems like a decent way to save for those who like to spend money, writing tests seems like a decent way to be careful for those who like to code fast.
(For those unfamiliar with software tests, it’s as if you are designing scientific experiments to verify your hypotheses about how the code works. If you claim that a virtual world you’ve designed now has gravity, how might I or anyone else — or even you yourself — believe you? If you also design an experiment whereby you pick up an object, hold it over the floor, drop it, and verify that a few seconds later the object is indeed on the floor, then we can all be assured that gravity at least works to that extent in your world.
And you really only need to design the scientific experiment once, because after the first time the computer can automatically run and report on all subsequent experimental outcomes. Add in something crazy like general relativity? No problem: if that experiment still succeeds, then we’ll be confident gravity still exists in some form. If instead, you implement general relativity so sloppily that objects start floating up towards the ceiling instead, then we would all be alerted to the fact that a formerly true belief about your world is now false. In this way, carelessness in coding can be somewhat mitigated by taking the time to design good experiments.)
I have learned to be careful around race conditions, no matter how unlikely they seem. I have learned to be careful about running any bit of code at least once before deploying, no matter how short the snippet is or how obvious it is that it must work or how hard it is to run. And now, I have probably learned to be more careful around researching the capabilities of existing software before succumbing to build fever. But is there any way I can be more careful in general for the new and novel situations of the future where this would matter?
Khmer font support on Mac OS
I want to rant about the problems I’ve had with reviewing Anki flashcards on the new Mac. You see, this is how the words ម៉ោង កម្លាំង should be rendered:

and it is in fact how they are rendered on Mac OS with Qt5, and on both Windows and Linux with Qt6.
This is how they were actually rendered on Mac OS with Qt6:

Damn! Well, the default Mac OS Khmer font “Khmer Sangam MN” fixes that, so I might as well just use that. Except then, I find out that ញ៉ាំ gets rendered as such:
You see, Khmer has this funky diacritic mark that looks like the English double quotes (and is informally called ធ្មេញកណ្ដុរ, or “mouse teeth”) that can appear on top of some consonants:

But if you want to add another diacritic mark on top, like a circle ំ, then the mouse teeth get moved down into a single apostrophe-looking thing at the bottom to avoid a collision, like so in this case where we add an ាំ to the ញ៉:

The above is how it’s supposed to look. Unfortunately the default Mac OS Khmer font does not do this. I’ve contacted Muthu Nedumaran, the creator of the script (and the reason why the font name has “MN” in it), to politely inform him of this problem. Heh, I can’t say why I bothered, but I did. I think part of me wants people to know that they’ve fucked up, even if they don’t care to fix it, so that they at least don’t get to continue living on thinking they’ve done nothing wrong. Chances are my message got shuffled into the spam folder anyways. Oh well.
So, next I tried Noto Serif Khmer. That fixed all of the above problems… but then I found out that words like បច្ចុប្បន្ន have the bottom apostrophe-looking diacritic mark ុ lopped off:

(Despite the visual similarities, this diacritic mark at the bottom is different from the mouse teeth getting moved down to the bottom. You can even have both this and the mouse teeth at the same time, as in the word ប៉ុន្មាន.)
To be somewhat fair, this is partially the font’s fault in not giving accurate character height data to the rendering program. For example, this is how the words ញ៉ាំ បច្ចុប្បន្ន and the words ស្រី លឿន look on separate lines with this font in Pages:

Notice all the diacritics interfering with each other. This is how it’s supposed to look:

(The diacritics are still too close for comfort here, but at least they display correctly even with zero line spacing.)
Also, as an aside, I have to note that the cursor is completely broken for Khmer text in Pages. Here, I have finished typing the second line, so the cursor should now be placed at the end of the second line. But instead, the blinking cursor always shows itself at the front:

Anyways, I finally discovered that the Battambang font works well across all three of the words ម៉ោង ញ៉ាំ បច្ចុប្បន្ន:

The only further thing I’ve noted is that អ៊ីចឹង looks like this:

instead of like this, the way I’m used to it being written:

This is another one of those Khmer alphabet things where the squiggly symbol ៊ is usually placed on top of consonants, but sometimes it’s placed under them instead when there are other diacritics on top. For example, add a hat ី to ស៊ and it becomes ស៊ី. But it turns out for the letter អ, both ways of writing អ៊ី are correct. Phew, I can finally end my font journey in peace!
Perhaps this experience can partially be chalked up to Apple’s historically poor support for Khmer. After all, the Mac still doesn’t have built-in support for the standardized NiDA keyboard layout; you’ll have to install the third-party Keyman keyboard instead. But to be fair, Keyman solves a number of Khmer typing problems that are also present on other operating systems, and this was also specifically a problem with Qt6 and Mac OS and certain Khmer fonts.
Sigh… oh well. I like to joke that I can’t get too mad at karmic retribution for all the bugs I’ve inflicted on innocent civilians before.
Half a year later
It’s been half a year since my inaugural blog post announcing version 0.1.0 of ZAMM on Valentine’s day. Since then, ZAMM hasn’t fundamentally changed. It still only does basic chat as its sole piece of real functionality. It still doesn’t actually do any of the metaprogramming automation that I want it to do. I don’t feel bad about this, because working on ZAMM has helped me learn a lot about myself. But I also don’t feel overly attached to ZAMM.
Perhaps at some point, it’ll be time to call it quits on this experimental AI tool — an experiment that failed not because the hypotheses turned out to be wrong, but one that failed because it never got to the stage of testing out the hypotheses in the first place. But I don’t think that point has come for me just yet. I wonder what awaits ZAMM and I in the next six months?